
Ask an Analyst, particularly a Digital Analyst, how they’d like to develop their career, and they are quite likely to tell you that they want to get into Data Science. But in fact the two disciplines (if they can even be described as separate disciplines) overlap considerably – some would even say completely. So what is the difference between Analytics and Data Science?
In my previous post I identified that Data Science comprises three main areas of work:
- Stakeholder engagement and storytelling
- Data analysis and preparation
- Model build, evaluation and deployment
Many analysts spend plenty of time in the first two of these activity areas: Evaluating and cleaning data, extracting insights (typically using descriptive analytics techniques, like segmentation and trending) and visualizing and presenting the results to business stakeholders and customers. In fact, compared to many Data Scientists, Analysts often have very deep skills in these areas, particularly around data storytelling and communicating results.
A useful conclusion, then, is that there are some things that Analysts do, which Data Scientists don’t; and some things that Data Scientists do, which Analysts don’t; and that there are is a lot of overlap in the middle.
The diagram below highlights what some of these activities and capabilities are, categorized into the slightly more generalized areas of Storytelling, Data Wrangling and Analytics & Modeling. A strong Analyst will have good capabilities in the first two columns; a strong Data Scientist will have good capabilities in the second and third columns.
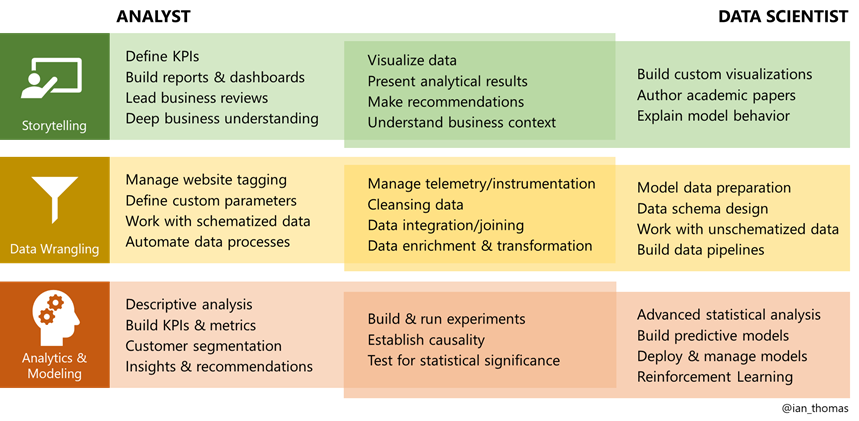
From Analytics to Data Science
As the above diagram implies, Analysts can (and should) pick which of three main capability areas they want to focus on first as they build out their Data Science skills – as, for that matter, Data Scientists should do the same as they build their Analytics skills. An Analyst who is already good at data visualization, for example, might decide to learn R or Python to build more advanced custom visualizations of data. Another Analyst might focus on learning how to apply predictive models (such as regression) to the datasets they work with in order to deliver more impactful analytics recommendations.
One of the nice things about the emergence of new Data Science/ML toolkits (such as Azure ML) in recent years is that it has made it possible for skilled Analysts to be able to build predictive models without having to understand the underlying math and algorithms from first principles. It is important to have a good grounding in the statistical foundations of Data Science, but in much the same way that it is no longer necessary to know how to build a car engine to drive a car, new tools have opened up this area to many new people (though there are some concerns among Data Scientists of a “dumbing down” of their discipline).
Building a balanced team
In Analytics, as in Data Science, people who are good at all three of the major capability areas are rare, and thus hard to find and expensive. If you’re building an Analytics/Data Science team, or looking to grow your existing Analytics teams’ capabilities in Data Science, I recommend you take a portfolio approach, hiring individuals who collectively provide coverage over all nine of the boxes in the diagram above, and who can work together effectively to execute projects for your stakeholders.
In particular, pairing individuals who are very deep on predictive modeling/ML with others who are stronger in stakeholder engagement and communication can be an effective approach – though you need to pay attention to “credit” issues, where one individual who has done a lot of behind-the-scenes work may feel like another individual who presents the results is taking the credit.
What about Data Engineering?
A third role type which comes into play in discussion of Analytics and Data Science is the Data Engineer. A lot of informal data engineering takes place in the “Data Wrangling” row of the skills matrix above, but a mature Analytics/Data Science organization needs to be able to rely on well-engineered (and well-maintained) data sources and pipelines, or unsustainable technical debt will quickly build up (a view shared by Emily Robinson in this post).
A good way to capture the relationship between Analysts, Data Scientists and Data Engineers is to look at Monica Rogati’s AI hierarchy of needs:

Data Engineers need to provide the foundations of the pyramid – data collection, movement/storage, and transformation/preparation – to enable Analysts and Data Scientists to build out the top part of the pyramid. Additionally, over time, the constructs (metrics, data structures, and models) that Data Scientists build should move down the pyramid and be productionalized by Data Engineers, so that the Data Scientists can move on and build the next great thing.
As with Analysts, many Data Engineers express interest in moving into Data Science. In this case they’ll build on their core foundation of technical data management/transformation skills, and augment these with analysis, modeling or data presentation skills.
The road ahead
Unsurprisingly there’s quite a lot of discussion about what it really means to be a Data Scientist and the path there from a more generalized Analytics role. For example, in this post, Elena Grewal discusses how she has evolved and grown the Analytics team at Airbnb and now has a number of Data Science “tracks”, which partially match up with the tracks in my framework above. I’ll continue to post links to interesting viewpoints on this topic in my Twitter feed.
Jim Sterne and I will be addressing this topic in a webinar for DAA members on September 18, laying out the DAA’s view on the relationship between Analytics and Data Science and talking about some concrete steps that Digital Analysts can take to grow their skills. Additionally, Tim Wilson of Search Discovery will be covering the topic in his keynote presentation at the DAA Symposium in Atlanta on October 30.
In the meantime, what do you think? Let me know your thoughts in the comments.
thanks for sharing nice information and nice article and very useful information…..