
As we’ve established earlier in this post series, Data Science is a process, with quite a lot of repetitive elements. Many Data Science projects involve a familiar set of tasks to identify, clean and prepare data, before finding the best model for the scenario at hand. And despite the mystique around the whole profession, many Data Scientists spend a lot of time complaining about all this repetitive work. But any repetitive process is ripe for automation, and Data Science is no exception. Enter the field of “AutoML”.
What is AutoML?
In the previous post in this series, we looked at the steps that a Data Scientist takes to select, train and tune models for the task they’re trying to accomplish:
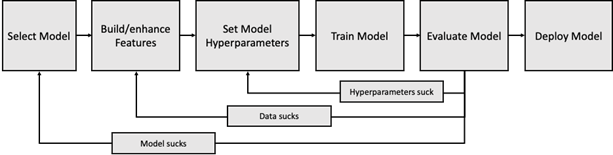
This process is highly iterative, which is a polite way of saying that it involves a lot of trial and error – to build a good model that has the best performance, the Data Scientist will need to take quite a few turns through the loops above, trying different models, tweaking the data’s features, and optimising the hyperparameters. This is all quite labour-intensive: different kinds of model require the data and features to be prepared in different ways, and there is an almost limitless number of ways in which a model’s hyperparameters can be tuned.
Additionally, the process of training and evaluating models is time-consuming – the Data Scientist has to wait while the model trains before they can evaluate its performance. This is reminiscent of the issue that programmers have when their code is compiling, captured so excellently by Randall Munroe at xkcd. The Data Science version is as follows:

This combination of repetitive (and repetitious) tasks and frequent waits for model retraining mean that the whole area of model build and optimization is ripe for automation. That’s what AutoML is designed to address.
AutoML (and Codeless ML) products
AutoML is the latest evolution in the democratization of Data Science, and builds on top of an overlapping generation of solutions that don’t have a snappy name, but which I shall call “Codeless ML”. These are solutions that dramatically reduce the amount of code a Data Scientist has to write in order to execute a Data Science project. A good example of such a system is Azure Machine Learning Studio, which provides a drag-and-drop interface for all of these tasks (including final deployment of the resulting model; another is KNIME’s Analytics Platform.
These “Codeless ML” platforms have done a lot to open up Data Science to a broader community of analysts, who may not have the R or Python coding skills (let alone the advanced knowledge of statistics and linear algebra) to write their own ML code. However, these self-serve tools still require their users to understand how to select and optimize an ML model, which can be quite complex – it runs the risk of a lot of not-very-good models being created and deployed.
The new generation of AutoML tools extends this “no-code” model to include and automate much of the Data Science process. This usually consists of the following tasks:
- Data pre-processing
- Data exploration (visualization)
- Feature engineering
- Feature extraction
- Feature selection
- Model training
- Algorithm evaluation and selection
- Hyperparameter optimization
Some tools also automate a series of tasks related to deployment and ongoing maintenance of models, which is another set of time-consuming tasks that may not impact an analytical Data Scientist, but could land on the plate of their colleague in the Data Engineering team. These tasks include:
- Model deployment (to cloud or end-point)
- Model performance tuning
- Model monitoring
- Model retraining
The number of solutions in this space is expanding rapidly, but here is a summary of some of the main commercial offerings that are available:
| H20 Driverless AI | AutoML platform with extensible “recipe” model – Data Scientists can bring their own recipes (e.g. scoring, regression) to extend the platform. Includes modules for NLP, time-series, visualization, deployment and interpretability |
| Amazon SageMaker Autopilot | Part of Amazon’s SageMaker, a suite of tools for Data Scientists. Provides model review and selection interface and integration with broader AWS services for production. Also provides a suite of functionality to deploy & monitor models. |
| Auger.AI | Developer-focused offering, to enable the “PREDIT” pipeline (Import/Train/Evaluate/Predict/Deploy/Review). Offers an API so that developers can integrate autoML into their code (e.g. instead of a complex CASE statement) and deploy on multiple cloud platforms. |
| Microsoft Azure AutoML | Part of broader Azure Machine Learning platform. Offers visual or notebook/code-first interface, automated feature selection, engineering and visualization, model performance review and selection, and transparency/fairness evaluation capability. Also offers ability to create pipelines & models through PowerBI studio tool. Deployment supported with some automation/optimization. |
| Google Cloud AutoML | AutoML offering structured around a set of 5 model scenarios: Natural Language, Translation, Video Intelligence, Vision, Tables (tabular data), vs being functionally oriented like most other platforms. Includes deployability & broader integration into GCP |
| DataRobot | Popular AutoML platform, supporting the “10 steps of automated machine learning”. Generates ensemble models, includes deployment and management, focus on explainability in generated models. Lots of deployment options (cloud, on-prem, hybrid, edge). |
| KNIME | Uses a “guided automation” approach – somewhere between pure self-serve UI-based model creation and full model automation. Extensible open-source platform via KNIME server. |
| BigML | Shared (publically-available) ML cloud platform – anyone can sign up and build models, with a Freemium model (with paid-for enterprise features. “OptiML” feature provides automated model selection/feature selection. Not obvious whether AutoML capabilities extend to deployment/ongoing model maintenance. |
| mljar | Another “free” platform to create models; relatively simple set of capabilities, no real automation extension into model deployment or management. Fairly simple functionality in data onboarding & other aspects of the AutoML pipeline (i.e. not tremendously extensible). |
AutoML and the “Citizen Data Scientist”
The emergence of Codeless and Automated Machine Learning tools has also given rise to one of the more unfortunate coinages of the Data & Analytics industry, that of “Citizen Data Scientist”. It seems that we have Gartner to thank for popularizing the term, which they define as:
“…a person who creates or generates models that use advanced diagnostic analytics or predictive and prescriptive capabilities, but whose primary job function is outside the field of statistics and analytics”
The idea in this definition is that anyone with a good understanding of their business, who has access to data, can use AutoML tools to create and deploy effective models. An example of this might be a marketer who feeds the data in their customer data platform into an AutoML tool to predict who is most likely to buy their product, and then uses this information to build segments for a CRM campaign.
The term has come under expert scrutiny from Tim Wilson, who has written eloquently about its origins in the perverse incentives of the software industry (which push the “this tool is all you need!” narrative), and the way it plays on the seductive idea that we can benefit from the magic of Data Science without having to properly understand its concepts ourselves, or hire someone who understands those concepts.
In reality, all the automagical functionality in the world will not deliver value without the person operating it having:
- A good understanding of the business context they’re operating in
- An understanding of the dataset they’re working with, and how it relates to the business context
- An appreciation of core concepts like uncertainty, accuracy and causality
- An understanding of the trade-off between accuracy and performance
Once you add these up, the profile of the person starts to look a lot more like an Analyst than a layperson moonlighting as a Citizen Data Scientist. And indeed, it’s Analysts who will most directly benefit from these more broadly accessible tools. In fact, acquiring a good foundational understanding of the areas above is essential for all Analysts as they look to keep their skills current and move from descriptive analytics into predictive and prescriptive analytics. That is, after all, the entire point of this series of posts.
That isn’t to say that the scenario I described above with the marketer isn’t valid – it can be very valuable to allow marketers to run predictive segmentation models against their customer data. It’s just disingenuous (and confusing) to imply those marketers are doing Data Science – they’re the downstream users of a system created by Data Scientists to help them do their jobs.
In choosing your AutoML tool, then, look for tools which do not claim to automagically solve every Data Science problem you will encounter, but ones which provide a flexible foundation to automate and simplify the more complex and burdensome parts of the discipline.
AutoML and the democratization of Data Science
More interesting than whether AutoML can enable non-Data Scientists to “do” Data Science is its ability to enable Data Scientists (or Analysts) to create pretty good ML models at dramatically reduced cost. This opens up a class of scenarios that would previously have been too time-consuming to pursue, bridging the gap between the old world of infrequently-built, expensive models and the future world of continuous optimization.
By way of example, consider a retailer with a large catalog of products, and a merchandizing/CRM team that spends its time promoting products on the website and delivering CRM campaigns to existing customers, to drive sales and manage things like stock aging. A full-blown AI-based approach to this problem would be to create a fully-integrated optimization platform which personalizes product placement on the site and delivers highly targeted outbound communication, based around a core recommendation/next best action engine.
The challenge with implementing a system like this is that it is very disruptive to almost every aspect of the way a traditional merchandizing/CRM team works – upending everything from data collection, to the martech platform, to the day-to-day workflow of creating campaigns. As I’ve written before, this kind of disruptive change is very hard for organizations to achieve, and can run into cultural resistance from people on the ground who are unconvinced that they should be replaced by robots.
AutoML offers the opportunity to take a somewhat more incremental approach which adds ML to existing workflows, and thus can ease skeptical teams into thinking in a more outcome-driven way. An Analyst or Data Scientist attached to the team can use AutoML to quickly create and deploy “quite good” models to predict optimal placement for a product, or a targeting segment for an email, in support of the current campaign-based workflows that the team uses. In this process they’ll learn a lot from the team about which product and customer attributes are important, and about the trade-off in incentives.
In parallel, a more involved Data Science Engineering effort can be taking place to create generalized recommenders and optimizers, alongside a longer-run change-management program to move the team towards optimization-based approaches. Crucially, the learnings from the “quite good” AutoML models will be invaluable in training and refining the longer-term solution, and in creating effective guard-rails for it.
AutoML can also broaden the use of ML in software engineering, replacing complex rules-based logic with a model-based approach which can reduce the chance of unhandled edge-cases when designing an application. This can be especially useful when building distributed systems, as it enables greater robustness for APIs and other public interfaces.
So AutoML is most definitely not a panacea or magic bullet for ML, any more than “no coding” visual application development tools have put software developers out of a job. But like IDEs, testing frameworks, code management platforms and other tools for coders have made their lives easier and raised their productivity, AutoML promises to do the same for the field of Data Science.
1 thought on “Demystifying Data Science, Part V: AutoML”
Comments are closed.