
As I mentioned in my first post in this series, the central purpose of Data Science is to find patterns in data and use these patterns to make useful predictions about the future. It’s this predictive part of Data Science which gives the discipline its mystique; even though Data Scientists actually only spend a relatively small fraction of their time on this area compared to the more workaday activities of loading, cleaning and understanding the data, it’s the step of building predictive models which unlocks the value hidden within the data.
What is a predictive model?
Previously, I talked about the old piece of weather lore that is used to predict whether the weather will be fine the next day:
Red sky at night, shepherd’s delight;
Red sky in the morning, shepherd’s warning.
This saying is in fact a predictive model. Let’s break it down.
A model is any simplified descriptive representation of reality. In this case the model is very simple, with just two attributes: Sky color and time of day. This model is then used to make a prediction: It says that if it is evening and the sky is red, then the next day the weather will be fine. It also says that if it is morning and the sky is red, then the weather that day will not be fine (as it happens, this prediction has some scientific basis).
Now imagine that you have a dataset which contains several sky color observations at different times of day:
| sky_color | time_of_day |
| red | 10:00 |
| blue | 13:00 |
| red | 20:00 |
| grey | 15:00 |
| red | 19:00 |
Given the model rules we just discussed above, we can write a bit of mathematical code (a function) that applies those rules to the values (known as features) in each row and come up with a weather prediction for that row. Assuming that “morning” is any time between 6am and noon, and “night” is a time between 6pm and midnight, the predictions are:
| sky_color | time_of_day | forecast |
| red | 10:00 | bad |
| blue | 13:00 | unknown |
| red | 20:00 | good |
| grey | 15:00 | unknown |
| red | 19:00 | good |
If the ‘red sky at night…’ rhyme were indeed a foolproof way of predicting the next day’s weather (which it’s not – it has nothing to say if the sky is not red), then our job would be done – we could just feed any future sky color observations into our little function and out will pop the weather forecast. But in practice, things are not that simple – we don’t know exactly what the rules are to predict the weather, and must work them out.
Enter Machine Learning
Traditional rules-based programming implements a fixed set of rules in code to achieve an output. For example, if you were writing software to control a cooling pipe valve in a power station, you would have a set of data that showed the known relationship between the position of the valve and the flow of water past it. You could use this data to control the flow of water precisely, using an explicitly coded ruleset.
Machine Learning, by contrast, is a technique to allow a computer to learn the set of rules for a model itself when those rules are not known in advance, through an iterative process of testing and optimization – a sort of computer version of Marco Polo.
As we covered above, a predictive model is essentially a function that uses the input variables to create a predicted value:
prediction = f(features)
Over the years, mathematicians have created various kinds of these functions, together with algorithms that can be used to ‘train’ (optimize) them. These algorithms (and the models they create) fall into three categories:
Supervised Learning: These models are trained using a ‘labeled’ data set, which is one where the value the model is trying to predict is already known (e.g. a set of house price data, or a set of pictures of cats). Once the model has been trained on this labeled data, it can make predictions when presented with a new set of data that has not been labeled (e.g. a set of house data without prices, or a random set of images). These kinds of models are looking to minimize their error – that is, how many times (or by how much) they are wrong.
Within this category there are two further types of model – classifiers, which are trying to classify the item being considered (e.g. “Is this a picture of a cat, or not?”) and regressors, which are those which are trying to predict a numeric value (e.g. “What is the likely value of this house?”).
This category gets its name from the idea that the training phase is ‘supervised’ – i.e. the model is told whether it got the answer right or wrong, or by how much – and this information is used to improve the model.
Unsupervised Learning: Models where there is no ‘right’ answer in the historical data. The best example of this kind of model is a clustering model – given a set of records (e.g. visitors to a website, or products in a catalog), how to cluster the records together into a set of meaningful groups? Because there is no ‘right’ answer, the objective of these models is to maximize some measure of effectiveness within the model, such as the tightness of the clusters themselves, or the distinctness of the clusters.
Reinforcement Learning: Models which are continuously updating themselves based upon new data that they are gathering in response to actions they are recommending. For example, an ad targeting system will be delivering ads to users (with a known set of attributes and historical engagement data) and then adding those users’ subsequent behavior to their data set and using this new data to make a new set of predictions about what to do next.
One of the misconceptions around Data Science and ML is that Data Scientists are coming up with new algorithms – that is, novel pieces of mathematics which are the foundations of the models they build. The actual creation of new Machine Learning algorithms is actually the preserve of academic research departments and the research departments of large technology firms. 99% of Data Science today is applying and tweaking popular algorithms that others have built. The process by which this happens is what we’ll cover next.
What the Data Scientist does
As the famous statistician George E. P. Box said:
“All models are wrong, but some are useful.”
All models are inaccurate to some extent, and part of the skill in Data Science is understanding how much inaccuracy is ok to live with. Fancy model algorithms exist (like convolutional neural networks) that can deliver slightly more accurate predictions – but at significantly higher computational cost.
Another factor in effective model design is explainability (also known as interpretability). Algorithms like neural networks can deliver good predictive results, but at the expense of being able to explain how they got there. Explainability is important because understanding how the model reached its conclusions can be useful for winkling out potential bias or issues with the model. Additionally, some industries require that the decisions made by predictive models can be explained to consumers – in consumer credit, for example, a lender must explain why they did not approve a loan.
All this means that the process of building a good model is highly iterative, balancing the above three considerations of accuracy, cost/complexity and explainability. The basic process is below:
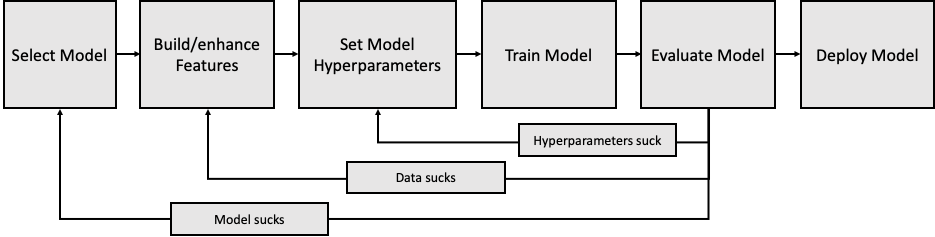
Let’s go through each of these steps in turn:
Step 1: Select Model
After the Data Scientist is done with data wrangling, which is to say they’ve loaded the data, taken some time to clean it up and understand it, they can start figuring out which model, with what configuration, will deliver the best results. The first step is to choose a model to work with.
The objective that the Data Scientist is aiming for will determine which of the three kinds of model they’re going to need to train. Based on what they’ve seen in the data, an experienced Data Scientist will have some idea of which model algorithms are likely to work well.
For example, Linear Regression is a relatively simple algorithm that produces quite good results against a set of features that are largely independent of each other. However, this might not be the best model for our weather prediction example above because the two input features (time of day and color of sky) are actually highly interdependent – it is only when both are present with certain values that the model makes an accurate prediction about the weather.
In practice a Data Scientist will try a number of different models against the same data and pick the one which performs the best, or combine their predictions (known as an ensemble approach).
Step 2: Build/enhance features
Once the Data Scientist has picked a model, they may need to do some additional feature engineering or feature selection to ensure that the dataset will work well with the model. The input data for a model may have dozens or hundreds of features (effectively, columns in the input data), not all of which will be useful for the model, and many of which will need to be mathematically manipulated to be useful (after all, Machine Learning algorithms are basically math equations in code – they need numbers as inputs). We covered some of the common scenarios for feature engineering in the previous post in this series.
Step 3: Set model hyperparameters
This sounds complicated, but it’s really just the process of setting some initial attributes of the model that will influence how it goes through its learning process, and therefore how effective it will be at the end of that process and how long the process will take. Many models, for example, train through a ‘walk’ along a mathematical gradient, trying to find the lowest (or highest) value on the curve. Setting the size of each step the algorithm takes as it makes that walk will determine how quickly the algorithm converges on the optimum value, but also how close it can get. This is a bit like trying to fix a wobbly table by sawing off pieces of its legs – if you can only saw off an inch at a time, the table will likely never be flat; but if you can only saw off a millimeter at a time, it may take a long time to ensure the table is flat.
Step 3: Train the model
In this step, the Data Scientist takes a portion of the data (say 70%) and feeds it (including the ‘answers’, i.e. the value the model is trying to predict) into the model algorithm and sets it loose. The algorithm then goes through the ‘walk’ process I mentioned above, trying to optimize the accuracy of its prediction, using the known answers. The training process stops when the model cannot get any better at predicting the answers – metaphorically, it gets to the top of a hill, and if it takes another step it starts going down the other side of the hill, so it stops and says “this is the best model I can produce”.
Step 4: Model evaluation
Once the Data Scientist has a trained model, they then run it against the portion of data that they held back (i.e. the remaining 30% in our example), and see how accurately it predicts the values it is meant to be predicting. Again, the purpose the Data Scientist is building the model for will determine how they feel about the accuracy of the model. Again: all models are inaccurate to some extent. The Data Scientist’s job is to minimize inaccuracy, and minimize the wrong kind of inaccuracy.
For example, if the Data Scientist is building a model to predict who may be at risk of a serious illness, it may be better to have a model that has more false positives (i.e. cases where it incorrectly identifies someone at risk when they are really not) than false negatives (cases where the model says someone is not at risk, when they are). On the other hand, a spam filter model may be more satisfactory if it tends to err on the side of false negatives (i.e. letting the occasional spam message through) rather than false positives (incorrectly flagging bona fide emails as spam).
What is almost certain is that once the Data Scientist has taken a look at the results of the model they will decide that something needs fixing: Either the hyperparameters for the model, or the data that went into the model, or the model selection itself. So they will go back to the appropriate step of the process, fix what they believe needs to be fixed, and run the model training process again.
Step 5: Model deployment
Once the Data Scientist has a model that they are happy with, they need to think about how to deploy the model. If the model has been created to produce a one-off analytical result (for example, attributing e-commerce revenue to different marketing channel spend), then deploying the model may simply be a case of running it against the entire dataset and presenting the results. But often the model will need to be run on a regular basis, perhaps very frequently, as part of a production system. In this case the model’s performance needs to be balanced with its accuracy, so the Data Scientist goes through a process of model tuning where they simplify the model a little bit and see if there is a meaningful impact on the model’s accuracy.
This trade-off will vary with the respective importance of accuracy and performance – a model that has to run in milliseconds, hundreds of times a second (such as a recommender service on a website) needs to be pretty efficient, and so accuracy may be traded off for performance. On the other hand, a model that is run only once a day on a handful of records (such as a medical diagnostic model) needs much better accuracy, so stakeholders may have to put up with the model running more slowly (or invest in more powerful hardware to run the model).
This process of model tuning and deployment may in fact be carried out by a different Data Scientist than the one who built the model – one with a lot more experience in writing production code, catching error conditions, and deploying to production. In the process of tuning the model, its original author may become outraged that their perfect model is being ‘damaged’ by tuning it for performance, and this (in my experience) is a common cause of friction within Data & Analytics teams.
In a future post I’ll talk about the different kinds of Data Scientist roles that exist, and how they can work together to reduce this kind of friction.
Secret Sauce
If you’re thinking, “Gosh, it sure seems like the Data Scientist has to spend a lot of time exercising judgment and making trade-offs”, then congratulations – you just identified the secret sauce of Data Science. A great Data Scientist accumulates a bunch of experience and context that enables them to make the judgments I described above, and quickly produce effective models. The rocket science isn’t in the models’ math itself – it’s in the creation of the best data and learning environment to maximize the effectiveness of a model, measured as a combination of its accuracy, cost and explainability.
YES, you are absolutely correct.I am also a Data science developer. I had done Data Science course from TGC India. They offer a variety of tutorials covering everything from the processes of Data Science to how to get started with Data Science.